Proper handling of file encoding can be a royal headache. Recently I spent an unreasonable amount of time trying to figure out why ZK’s Fileupload component was messing with the contents of my CSV file:
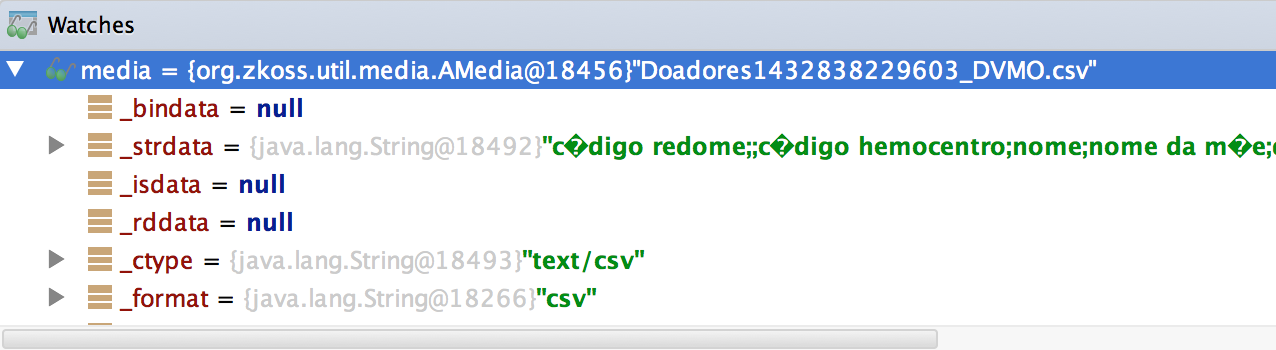
The data should be: código redome;;código hemocentro;nome;nome da mãe;
The file was generated with Windows Excel, using the encoding ISO-8859-2
(common encoding for Windows). After some investigation I found
out that Fileupload by default treats all files with content type text/...
as UTF-8! Ouch!!
If all your files will be generated using the same file encoding, this can be fixed with the following configuration:
1 2 3 4 5 6 7 | |
The upload-charset tag did the trick! But what if my user decides to move to a different (better?) platform in the future, and generates the file with UTF-8? Or any other encoding?
Then the proper solution is to use the tag upload-charset-finder-class:
1
| |
The documentation says that this class has to implement
the interface CharsetFinder
and its sole method String getCharset(String contentType, InputStream content):
When a text file is uploaded, the getCharset method is called and it can determines the encoding based on the content type and/or the content of the uploaded file.
Which leads us to the main reason of this post: How to detect the file encoding, if ZK itself does not provide a default implementation for this interface?
More research pointed me to some solutions, but the one that I ended up implementing was using the
Apache Any23. It includes the TikaEncodingDetector,
that can be used to auto-detect the file encoding of a stream. The final code
for the CharsetFinder implementation is the following:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Yep, it is that simple. The final ZK configuration to use this class is:
1 2 3 4 5 6 7 | |